Posted inHow tos Linux Miscellaneous Make http request with telnet How to make an HTTP request with telnet One of the most frequent interview question for tech professionals,… Posted by daniel September 14, 2019
Posted inHow tos Linux Miscellaneous Linux – find a file by inode number In Linux, the find command is most commonly used to search files using different criteria such as file… Posted by daniel September 4, 2019
Posted inHow tos Linux Miscellaneous Linux – show file system type How to print the file system type of a mount Linux supports several file systems, including VFAT, ext2,… Posted by daniel September 4, 2019
Posted inHow tos Linux Miscellaneous Linux : using zip to compress or decompress files There are several tools for compressing and decompressing files in Linux, you can get a summary of these… Posted by daniel May 10, 2019
Posted inHow tos Linux Miscellaneous Linux – Find and replace text in multiple files Contents of most text files change during the life of the file , and it is common to… Posted by daniel May 8, 2019
Posted inHow tos Linux Scripting Installing Google Cloud SDK in Linux How to install Google cloud platform(GCP) sdk - gcloud cli tool The instructions below were testing in Ubuntu… Posted by daniel November 11, 2018
Posted inHow tos Linux Scripting Ansible : Run playbooks as a script Ansible : How to run playbooks as a shell script Ansible is a powerful tool for automation, its… Posted by daniel November 11, 2018
Posted inHow tos Linux Miscellaneous How to find the type of storage engine a MySQL table uses What type of storage engine a MySQL table uses? MySQL supports several storage engines such as InnoDB, MyISAM,… Posted by daniel August 22, 2018
Posted inContainers How tos Linux iptables – table full and dropping packets nf_conntrack: table full, dropping packet I actually saw this error in a Docker host, and Docker uses iptables… Posted by daniel June 18, 2018
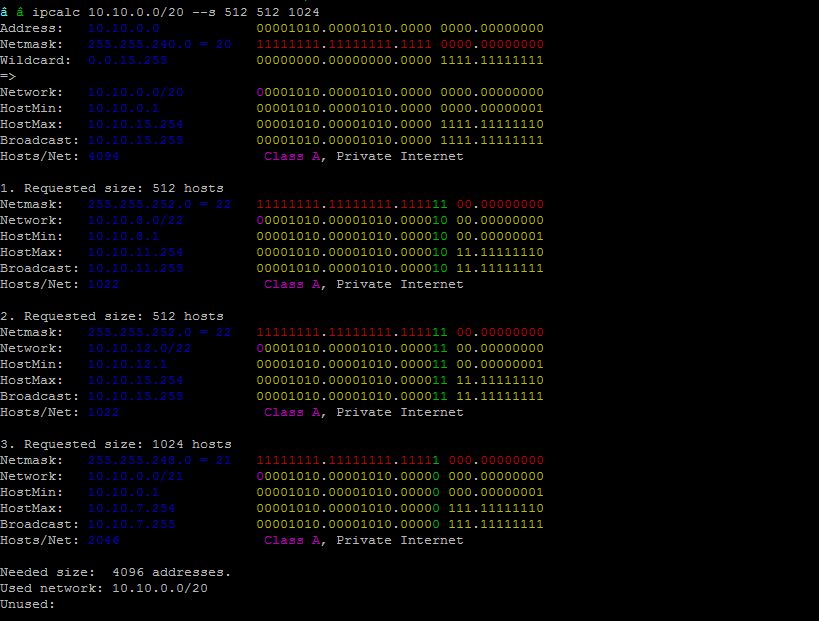
Posted inHow tos Linux Scripting IP subnet calculator Linux - IP subnet calculation with ipcalc ipcalc is a program to perform simple manipulation of IP addresses… Posted by daniel May 30, 2018